Building a Synthetic Caregiver: Fine-Tuning Language and Speech Models for Child Language Acquisition
Introduction
Understanding how young children acquire language is a complex and fascinating field of research that I have been introduced to through my collaborators. A relevant factor is the unique form of communication known as child-directed speech (CDS), which is essentially speech (usually from the caregiver) directed towards the child. CDS is often characterized by its simplified grammar, exaggerated “sing-songy” intonation, and focus on the immediate environment. CDS is at the cornerstone oh how kids learn to speak, and specifically, CDS provides crucial input for children as they learn to connect sounds, words, and meanings.
Our intention here is to study the precise impact of different CDS features on language learning in children, using speech and language AI models as our test subjects for the caregiver and the child. While valuable resources for studying child-directed speech exist, such as the (CHILDES) database, these recordings often contain a large amount of noise and auxiliary interactions, including the children’s responses and other background sounds. This makes it difficult to isolate the specific linguistic or acoustic properties of the caregiver’s speech that are most influential in language acquisition. Ideally, we’d want a system that generates speech in the cadence of child-directed speech, on cue, providing clean and controlled input for experimental purposes. To achieve this, we can use a processed and carefully selected subset of datasets like CHILDES to train our Caregiver Robot, ensuring it learns the core characteristics of CDS while minimizing the influence of extraneous audio. This article focuses on the core of the Caregiver Robot: the fine-tuning of cutting-edge language and speech models. I will be writing another article in the near future containing the second part of this work where we build the Child-Learner Robot, and the interactions between them.
Fine-Tuning Gemma
The first step in building our synthetic caregiver was to create a system capable of generating appropriate text. We chose Gemma, a robust open-source language model from Google, as our foundation. However, a general-purpose LLM doesn’t inherently “speak” like a caregiver. To resolve this, we employed a technique called Low-Rank Adaptation (LoRA) fine-tuning.
LoRA is an efficient method for adapting large language models to specific tasks or domains. Instead of retraining the entire language model (a computationally expensive process), LoRA modifies only a small subset of the model’s parameters. This allows us to tailor Gemma’s output to the characteristics of CDS while preserving its general language capabilities.
The key to successful fine-tuning is the training data. We used a carefully curated dataset of child-directed speech, primarily derived from the Child Language Data Exchange System (CHILDES) database. CHILDES is a large, publicly available collection of transcribed caregiver-child conversations. We focused on the English portion of CHILDES, selecting a processed subset with clear, well-formed examples of child-directed speech. This provided the vocabulary, sentence structures, and overall style typical of these interactions.
After preparing the CHILDES data, we used it to train Gemma with LoRA, through Unsloth. We essentially showed the model many examples of child-directed speech by giving the LoRA training process the processed CHILDES data, along with the prompt, “Here’s an example of child-directed speech.” This taught the model the patterns and style of caregiver language. Once the training was complete, we could then prompt the LoRA-trained Gemma model to generate new phrases that a caregiver might say to a child, effectively creating our synthetic caregiver’s ‘voice’.
Fine-Tuning Tortoise-TTS for Speech
Generating appropriate text is only half the battle. To create a truly convincing synthetic caregiver, the next step was to synthesize speech that captured the characteristic prosody of CDS – the “sing-songy” quality, slower speaking rate, and clear enunciation. For this, we used Tortoise-TTS, a state-of-the-art text-to-speech (TTS) system known for its ability to generate highly expressive and natural-sounding speech.
While Tortoise-TTS is capable of producing a wide range of voices and styles, we specifically configured it to emulate CDS. This involved adjusting parameters related to:
-
Pitch Range: We increased the pitch range to create the characteristic melodic intonation of CDS.
-
Speaking Rate: We slowed down the speaking rate to a pace more suitable for young children learning to process language.
-
Clarity: We ensured that the enunciation was clear and distinct, aiding comprehension.
We used the preset parameters of Tortoise-TTS to generate the characteristic speech.
Evaluation and Results
The ultimate test of our Caregiver Robot was to evaluate the quality of both the generated text and the synthesized speech. We employed a combination of automated metrics and human evaluations.
For the text, automated metrics (perplexity, BLEU score, type-token ratio) showed that the LoRA-fine-tuned Gemma model significantly outperformed the base model in generating CDS-like text. Human evaluators, including linguists and educators, confirmed that the generated text was grammatically correct, appropriate for a young child audience, and natural-sounding.
For the speech, automated metrics like Mel-Cepstral Distortion (MCD) indicated good acoustic quality. Crucially, human evaluators rated the synthesized speech as highly intelligible, natural, and possessing the desired CDS characteristics. Below are some example output files generated from the Caregive Robot.
Caregiver Robot outputs -
Conclusion and Future Work
The successful fine-tuning of Gemma and Tortoise-TTS has resulted in a powerful and useful Caregiver Robot. This system can generate a consistent and controllable corpus of synthetic child-directed speech, opening up new avenues for research in child language acquisition.
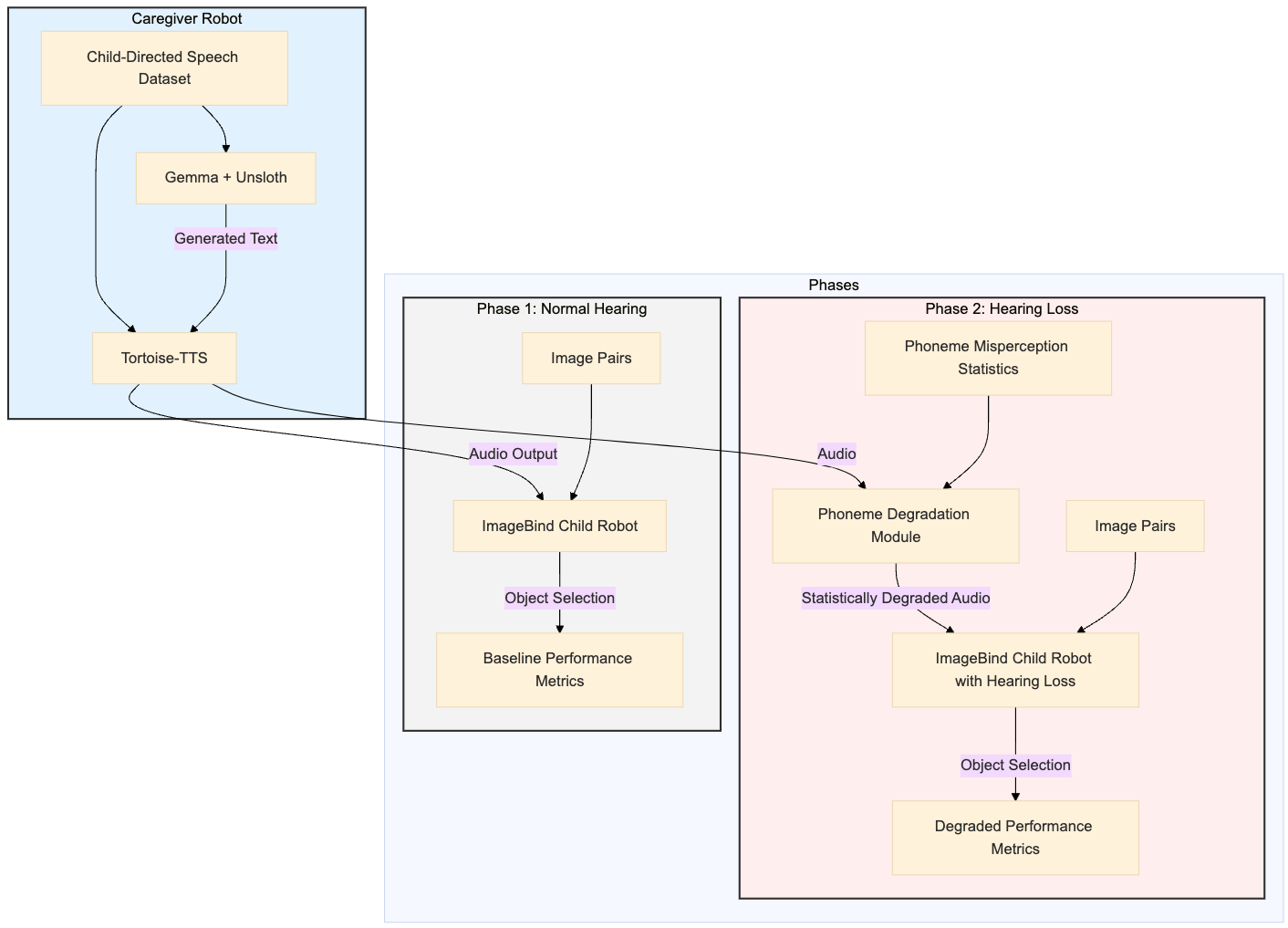
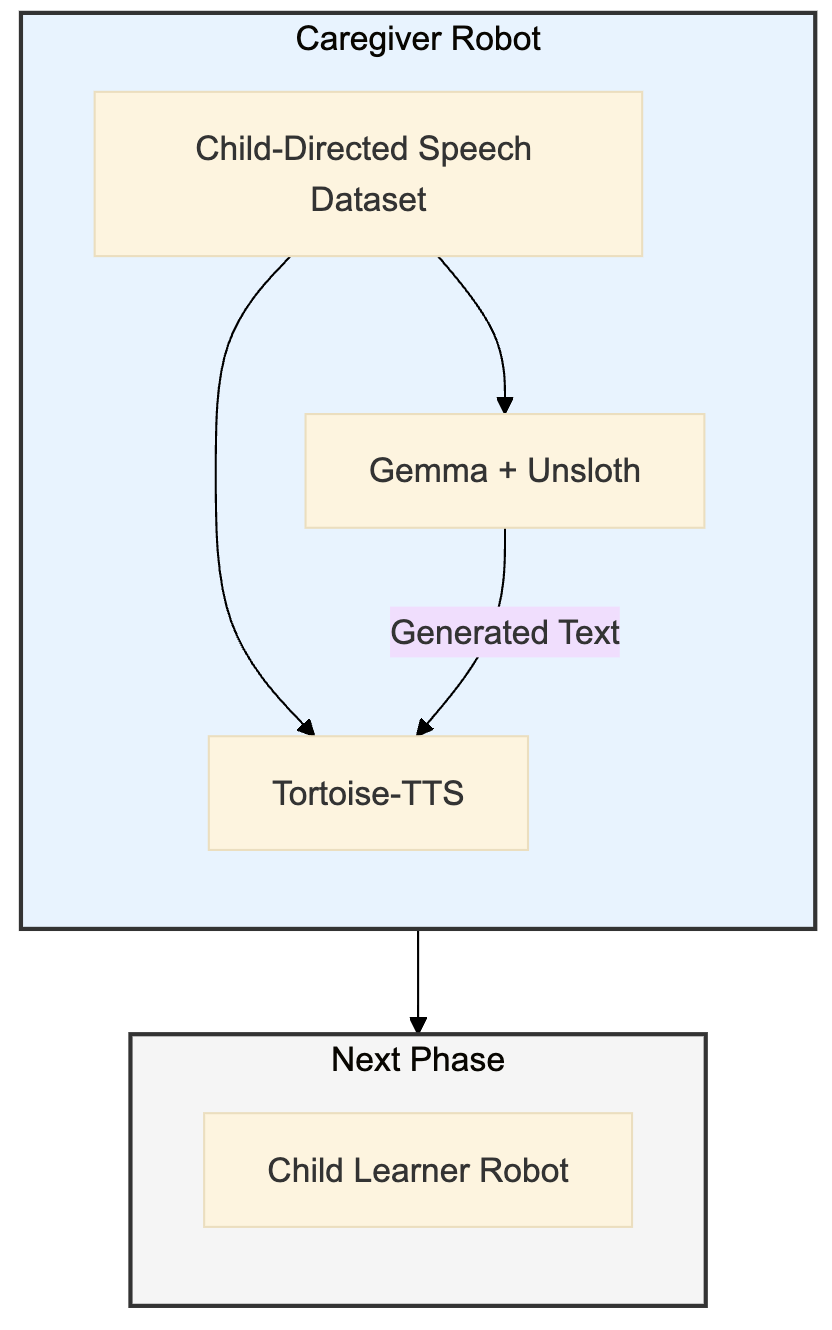
By precisely manipulating the linguistic and acoustic features of the generated CDS, we can now systematically investigate their impact on a simulated child language learner. This is particularly valuable for studying the effects of hearing loss, where controlled manipulation of the auditory input is crucial. The Caregiver Robot represents a significant step forward in our ability to model and understand the complex dynamics of early language development. Future work will focus on integrating this system with a simulated “Child Learner Robot” to explore these dynamics in detail. Shown below is a flowchart of the planned work. We hypothesize that as we systematically degrade the quality of caregiver speech that the child with hearing loss hears, that the Child Robot’s performance on the language acquisition benchmark will worsen.