Improving the performance of classification models
This post is a continuation of the previous post, where a few classification algorithms were used to predict the income class. Here, we will take several steps to improve the prediction accuracy. Just to reiterate, we will use a popular dataset to predict income class (whether a person of the population makes more than 50K or not). The dataset is available on UCI Machine Learning database: https://archive.ics.uci.edu/ml/datasets/census+income.
We will pick up where we left off in the previous post. We found that Random Forest classifier gave the best performance among the four classifiers used.
Random Forest: Baseline accuracy=0.857
We will use three different approaches to attempt to improve the predictions:
- GridSearchCV - an exhaustive search in the parameter space to find the best parameters.
- Ensemble methods - an ensemble of many base estimators are used to improve the performance of prediction.
- Additional feature engineering - we did some feature engineering already in the previous post, but we will go into more detail here.
Additional Feature Engineering
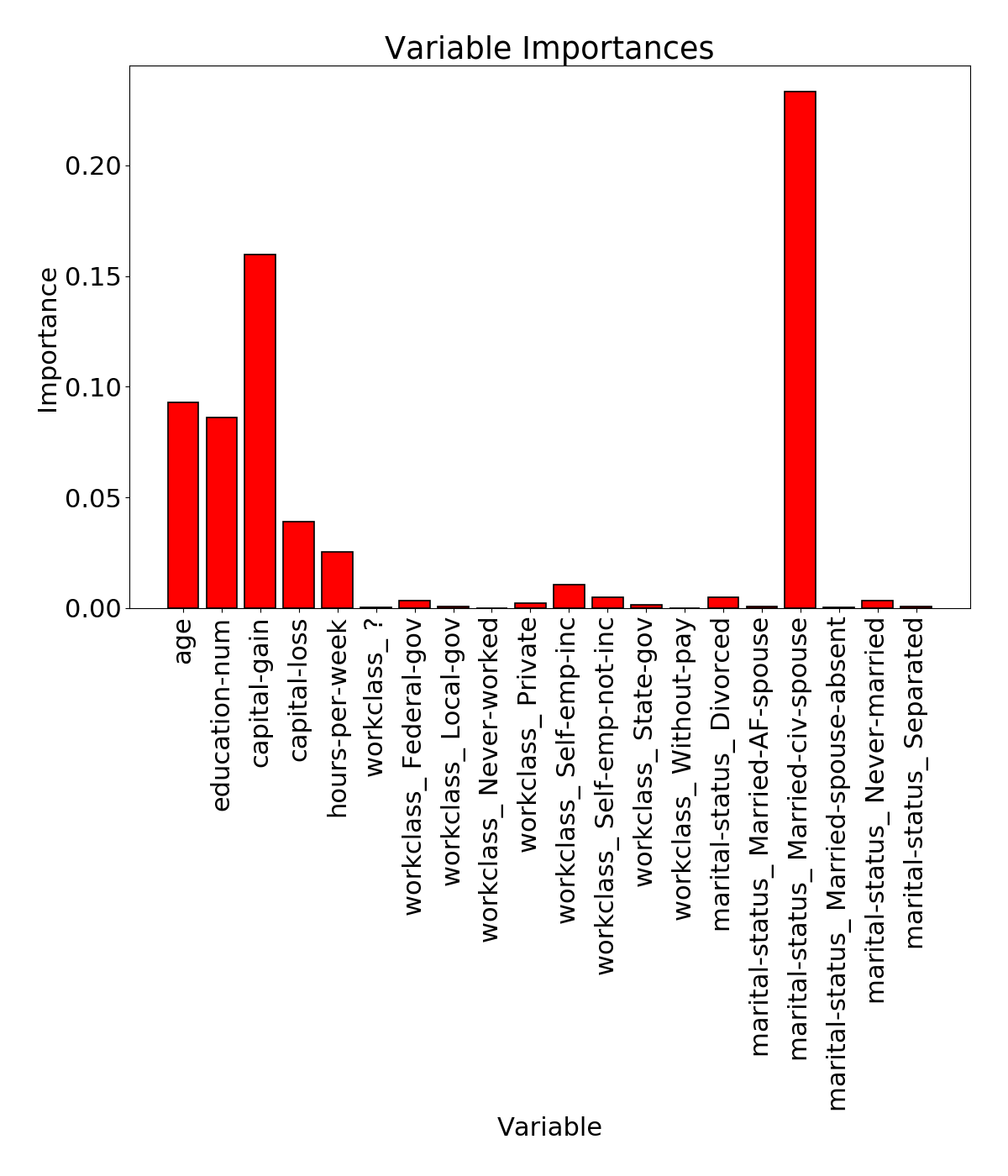
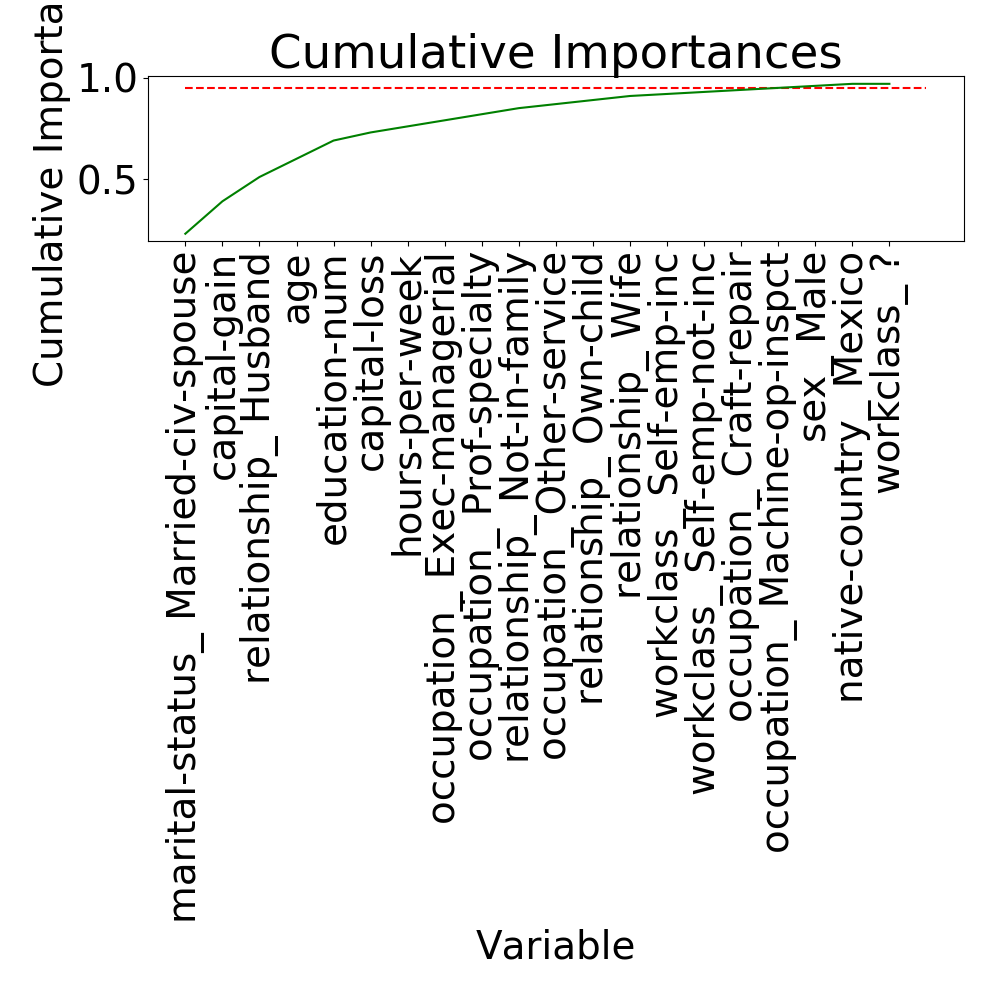
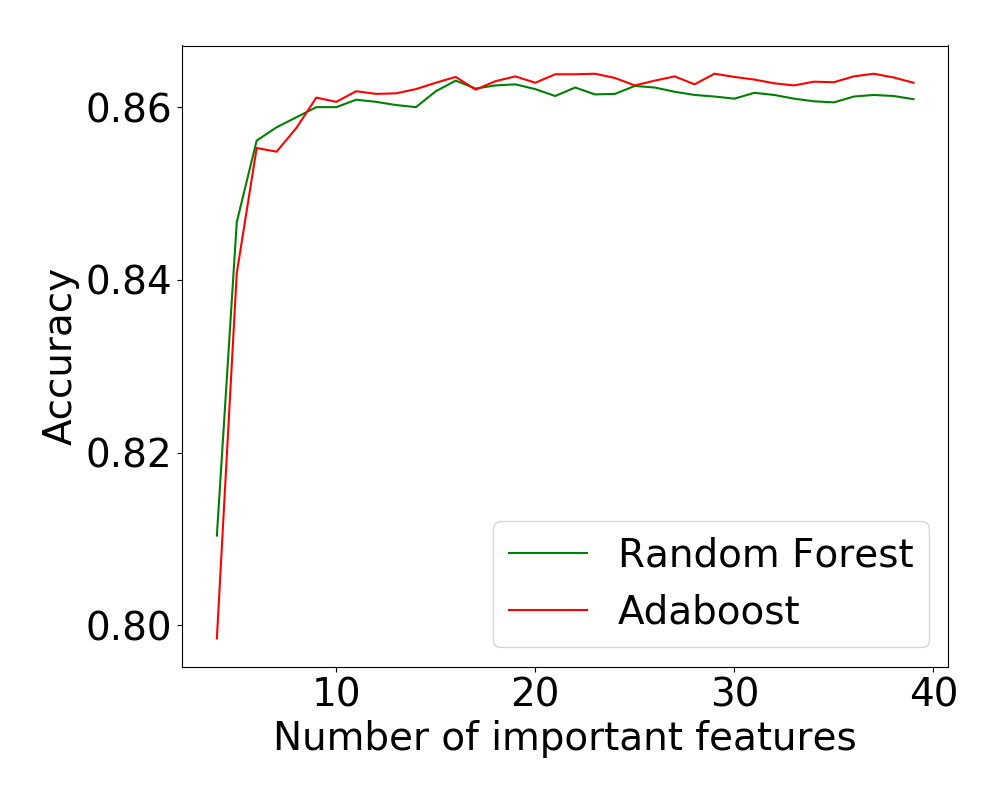
We will first use GridSearch to find the best parameters to improve the performance of the Random Forest classifier.
{'bootstrap': True, 'max_depth': 20, 'max_features': 3, 'min_samples_leaf': 3, 'min_samples_split': 8, 'n_estimators': 1000}
Random Forest: Grid Search accuracy=0.864
Next, we will use ensemble methods starting with AdaBoost, where we fit a classifier with 1000 weak learners:
AdaBoost accuracy=0.862
This is not better than the parameter-optimized Random Forest algorithm.
Gradient Tree Boosting is a generalization of boosting to arbitrary differentiable loss functions.
Gradient Boosting classifier accuracy=0.862
There’s so much more we can do with the dataset but this has already been a long post. More to come next time.