Fine-Tuning Methodology for the Caregiver Robot: Age-Stratified Language Model Training
Introduction
This post details our methodology for fine-tuning language models to generate authentic child-directed speech for the Caregiver Robot system. Building upon our previous work, we introduce a novel approach using age-stratified model training to capture how caregivers naturally adapt their speech patterns as children develop. By creating specialized models for different developmental stages, we enable precise study of the relationship between linguistic input and language acquisition.
A key challenge in child language acquisition research has been controlling for the natural variability in caregiver speech. This makes it difficult to isolate specific factors that drive language learning. Our artificial system addresses this by generating developmentally appropriate child-directed speech in a controlled way, opening new possibilities for systematic investigation of language acquisition mechanisms. The models can produce consistent linguistic input while varying targeted features, allowing for controlled experiments that would be impossible with human caregivers.
Methodological Overview
The core of our approach involves fine-tuning Facebook’s OPT-350M transformer model using carefully curated, age-stratified data derived from the Child Language Data Exchange System (CHILDES) corpus. We selected OPT-350M as our foundation model due to its optimal balance between computational efficiency and linguistic capability, providing sufficient model capacity to learn complex language patterns while remaining tractable for multiple parallel training runs.
Our approach involves training both age-specific models for distinct developmental ranges and a unified model trained on data across all age ranges. The age-specific models capture linguistic characteristics that caregivers use when interacting with children at particular developmental stages, while the unified model learns general patterns of child-directed speech adaptation over time. Such a strategy allows us to compare the effectiveness of specialized versus general approaches in modeling caregiver speech patterns.
Age Stratification Strategy
We partitioned the data into three developmental periods based on established child language acquisition milestones:
- Early Period (3-15 months): Pre-linguistic and early babbling stage
- Middle Period (15-27 months): First words and early vocabulary explosion
- Late Period (27-45 months): Grammar development and complex sentence formation
This stratification captures the natural progression of caregiver speech adaptation, from highly simplified, repetitive utterances to more complex linguistic structures.
Data Preprocessing Pipeline
Dataset Integration and Cleaning
Our preprocessing pipeline begins with comprehensive data integration from multiple CHILDES corpora:
def clean_text(text):
if not isinstance(text, str):
return ""
text = re.sub(r'xxx+|www+', '', text) # Remove transcription artifacts
text = re.sub(r'\b\d+\b', '', text) # Remove isolated numbers
text = re.sub(r'\s+', ' ', text) # Normalize whitespace
return text.strip()
The cleaning function addresses common transcription artifacts in CHILDES data, including standardized notation for unintelligible speech (xxx) and incomplete words (www). We preserve numerical content when it appears in meaningful linguistic contexts while removing isolated digits that typically represent transcription codes.
Age Range Processing
A critical component of our methodology involves extracting meaningful age information from the heterogeneous age representations in CHILDES:
def extract_min_age(age_range):
if not isinstance(age_range, str): return None
try:
age_str = age_range.split('-')[0].strip()
match = re.match(r'^\d+', age_str)
return int(match.group(0)) if match else None
except Exception: return None
This function handles various age format inconsistencies in the corpus, extracting the minimum age from range representations. We focus on the minimum age as it provides the most conservative estimate of the child’s developmental stage.
Model Architecture and Training Configuration
Base Model Selection
We selected Facebook’s OPT-350M as our foundation model for several reasons:
- Computational Efficiency: The 350M parameter size provides a balance between model capacity and training feasibility
- Open Source Availability: Full model weights and architecture details are publicly available
- Proven Performance: Demonstrated effectiveness on language generation tasks
Fine-Tuning Strategy Decision
Our initial approach involved Low-Rank Adaptation (LoRA) fine-tuning, which offers computational efficiency by updating only a small subset of model parameters. However, preliminary experiments with LoRA on child-directed speech data produced unsatisfactory results. Quantitative analysis revealed that the generated text had significantly different Type-Token Ratios (TTR), word frequency distributions, and Mean Length of Utterance (MLU) compared to the original CHILDES corpus, indicating that the model failed to capture the core linguistic patterns of child-directed speech.
Given these limitations, we pivoted to full fine-tuning, which updates all model parameters and provides greater capacity for learning domain-specific patterns. While computationally more expensive, full fine-tuning proved necessary to capture the complex linguistic adaptations present in child-directed speech. The choice of OPT-350M represented an optimal compromise: large enough to learn sophisticated linguistic patterns through full fine-tuning, yet small enough to remain computationally tractable for training multiple age-stratified models in parallel.
Training Hyperparameters
Our training configuration prioritizes stability and generalization:
training_args = TrainingArguments(
output_dir=model_dir,
per_device_train_batch_size=4,
gradient_accumulation_steps=8,
learning_rate=2e-5,
max_steps=10000,
logging_steps=50,
save_steps=500,
eval_steps=500,
save_total_limit=2,
load_best_model_at_end=True,
metric_for_best_model="loss",
greater_is_better=False,
fp16=torch.cuda.is_available(),
lr_scheduler_type="linear",
warmup_steps=500,
gradient_checkpointing=True,
)
The effective batch size of 32 (4 × 8 gradient accumulation) provides stable gradient estimates while remaining within GPU memory constraints. The learning rate of 2e-5 follows established best practices for fine-tuning transformer models on domain-specific data.
Stratified Training Approach
Data Splitting Strategy
For each age group, we implement stratified sampling to ensure representative train/validation splits:
if stratify_col in group_data.columns:
value_counts = group_data[stratify_col].value_counts()
if (value_counts < 2).any():
stratify_values = None # Disable stratification for small classes
else:
stratify_values = group_data[stratify_col]
This approach maintains speaker distribution across splits, preventing overfitting to particular caregiver speech patterns while ensuring sufficient diversity in both training and validation sets.
Tokenization and Sequence Processing
Our tokenization strategy addresses the specific characteristics of child-directed speech:
def tokenize_function(examples):
texts = [str(text) + tokenizer.eos_token for text in examples["text"]
if isinstance(text, str)]
tokenized_output = tokenizer(
texts,
padding="max_length",
truncation=True,
max_length=256,
return_tensors="pt"
)
return tokenized_output
The 256-token maximum length accommodates the typically shorter utterances in CDS while preventing computational overhead from longer sequences. The explicit addition of end-of-sequence tokens ensures proper boundary detection during generation.
Model Evaluation Framework
Validation Strategy
Each age-stratified model undergoes continuous evaluation during training using held-out validation data from the same age group. This approach ensures that model performance metrics reflect age-appropriate language generation capabilities.
Cross-Age Generalization
While our primary focus is age-specific performance, we also evaluate cross-age generalization by testing each model on validation data from other age groups. This analysis provides insights into the transferability of learned linguistic patterns across developmental stages.
Results
To evaluate the effectiveness of the outputs of our fine-tuned models, we conducted linguistic analysis comparing the generated utterances against two key reference corpora. First, we compared model outputs to the holdout validation set from the original CHILDES dataset to assess how well the models captured authentic child-directed speech patterns. Second, we compared the generated CDS against adult-directed speech corpora to verify that our models maintained the distinctive characteristics that differentiate child-directed from adult-directed communication.
We used several standard linguistic metrics to quantify the models’ performance:
- Moving Average TTR: Provides a stable measure of lexical diversity (ie, the ratio of unique words to total words) across varying text lengths
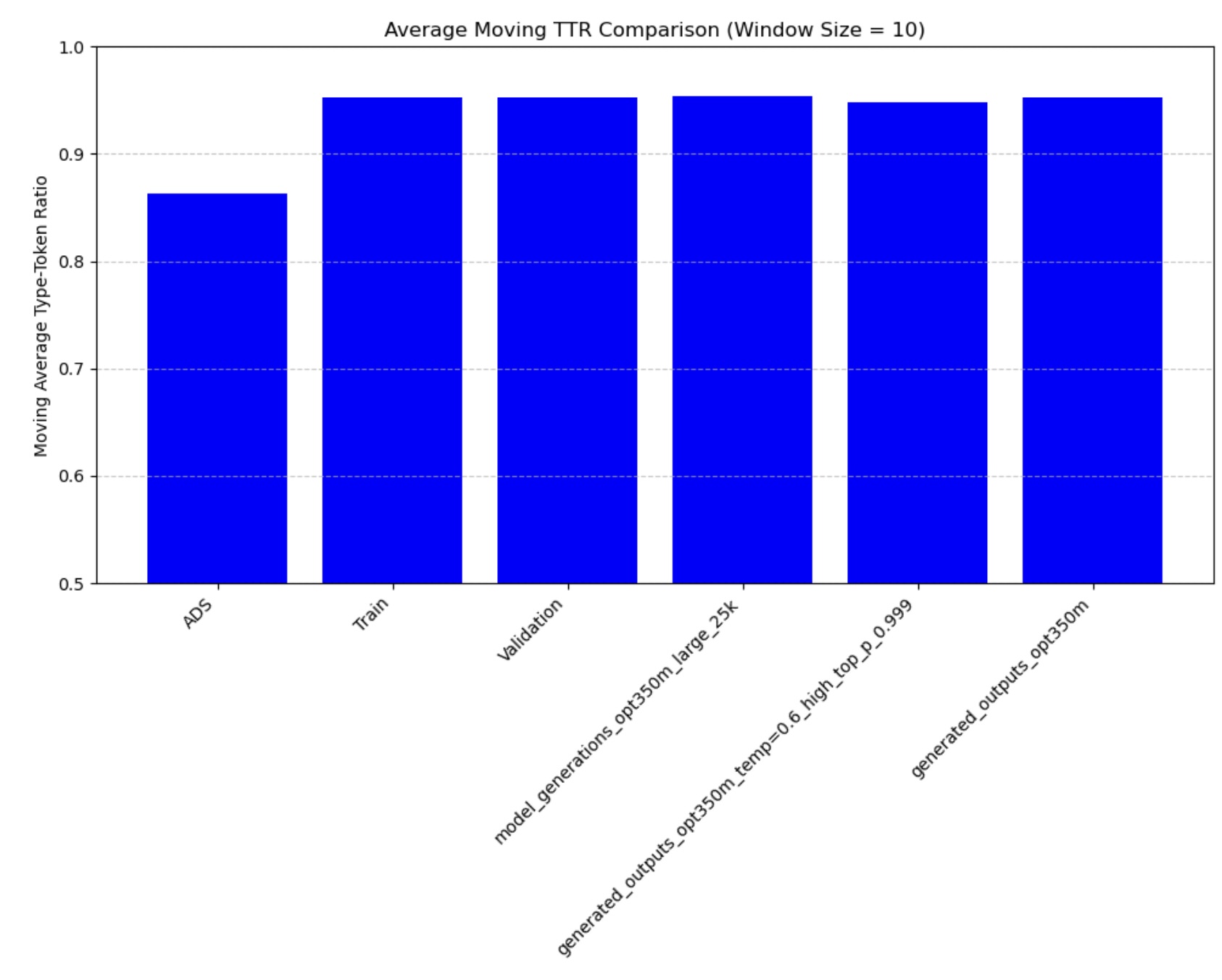
Figure 1: Moving Average Type-Token Ratio across all age groups
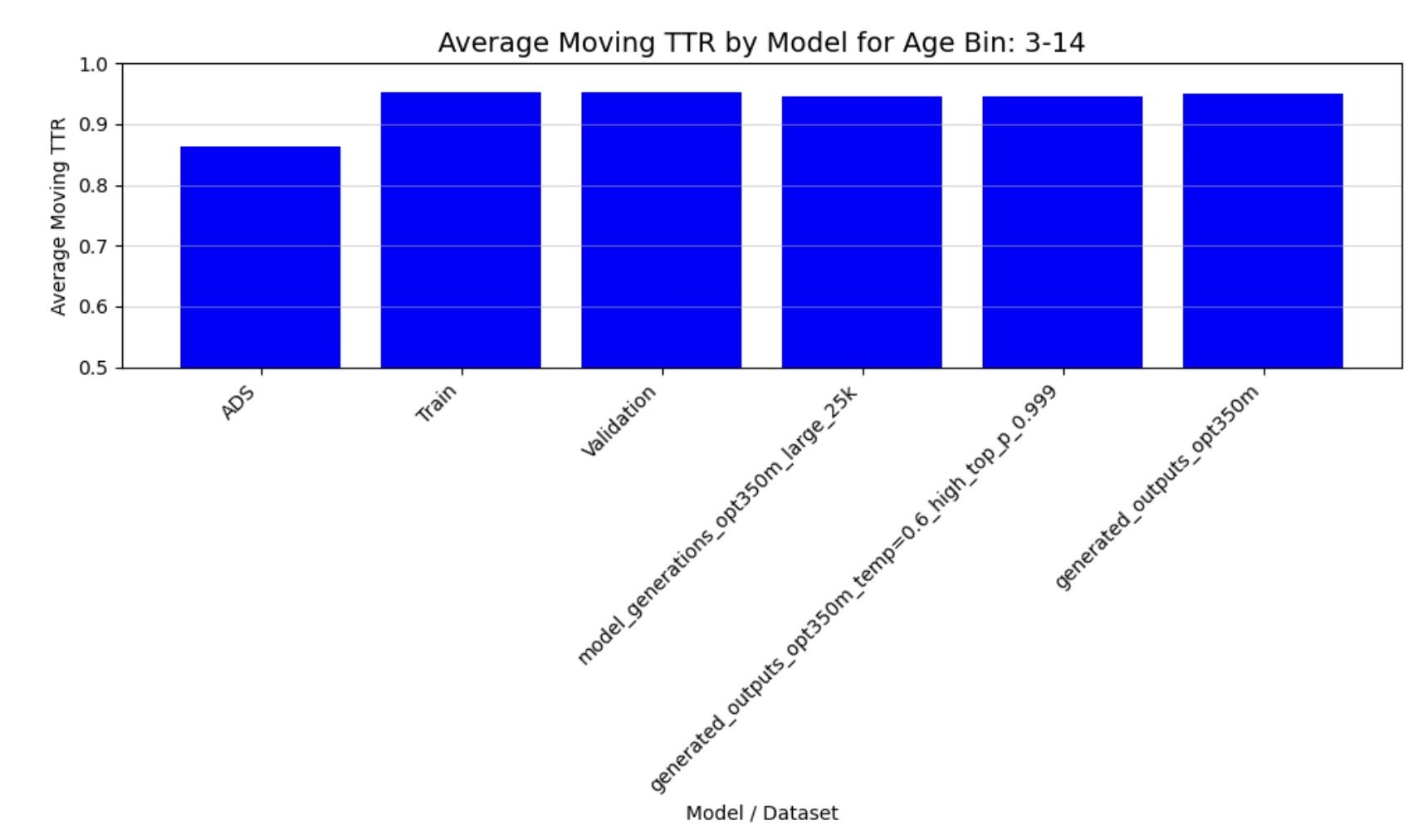
Figure 2: Moving Average TTR (3-14 months)
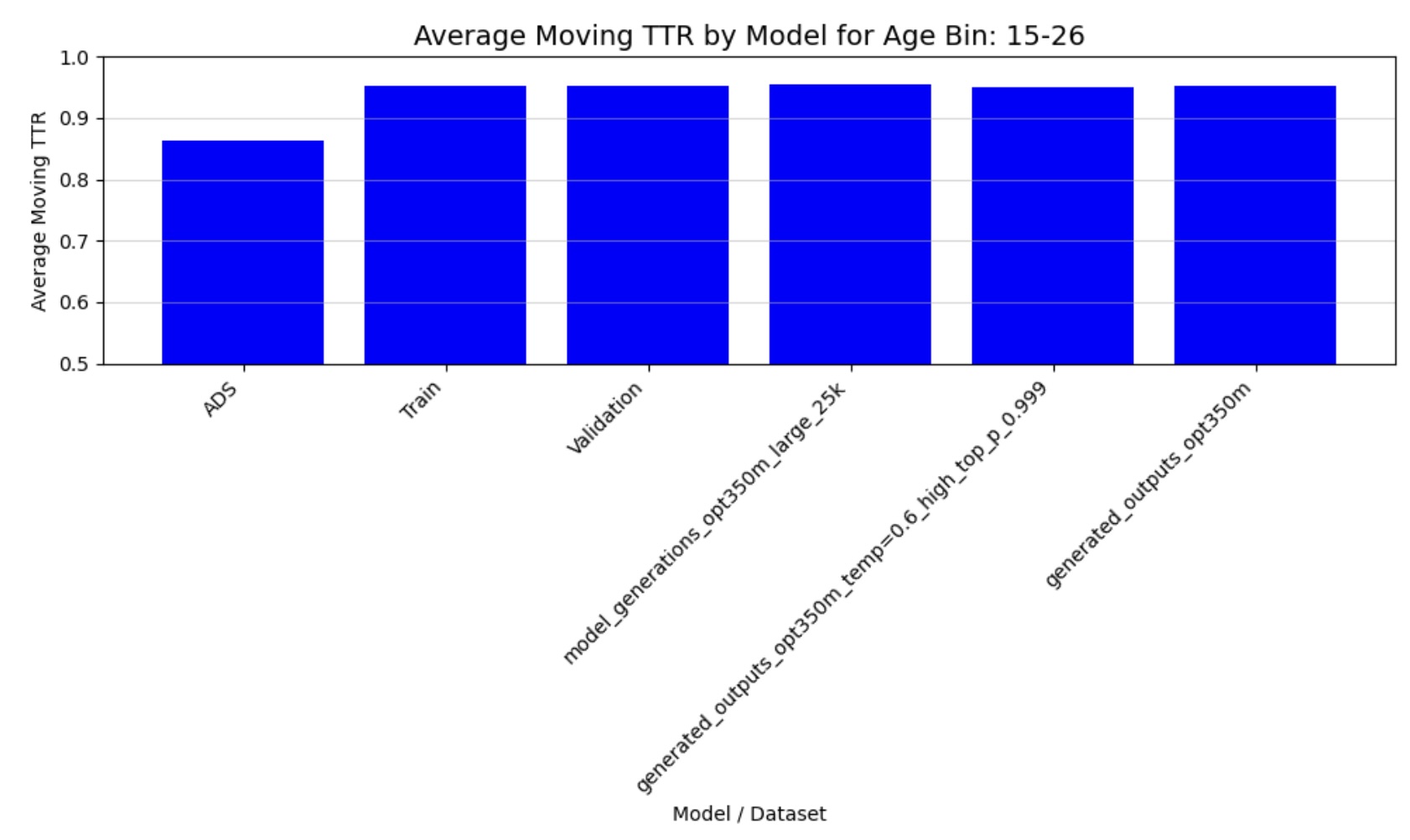
Figure 3: Moving Average TTR (15-26 months)
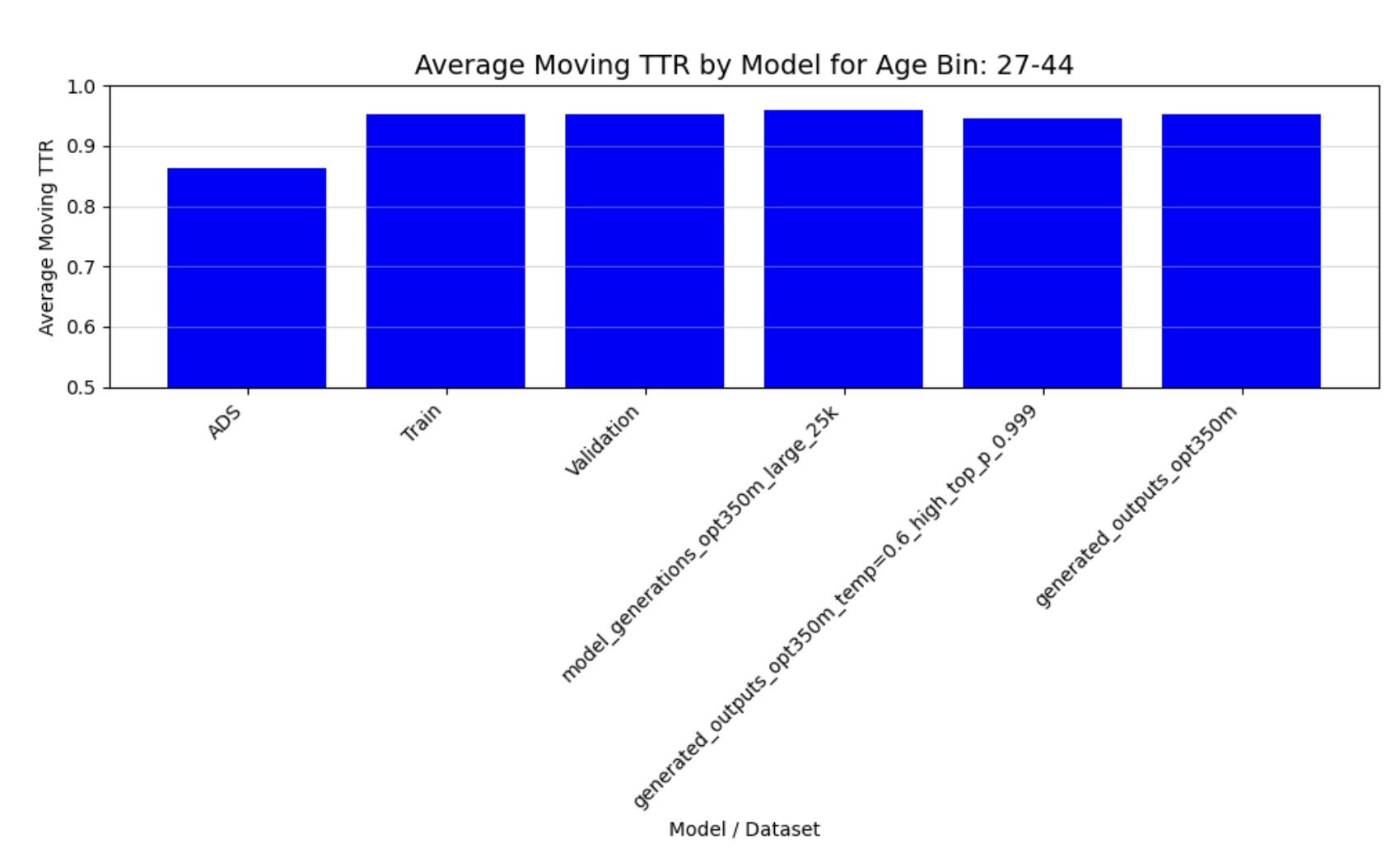
Figure 4: Moving Average TTR (27-44 months)
- Mean Length of Utterance (MLU): Quantifies syntactic complexity through average utterance length
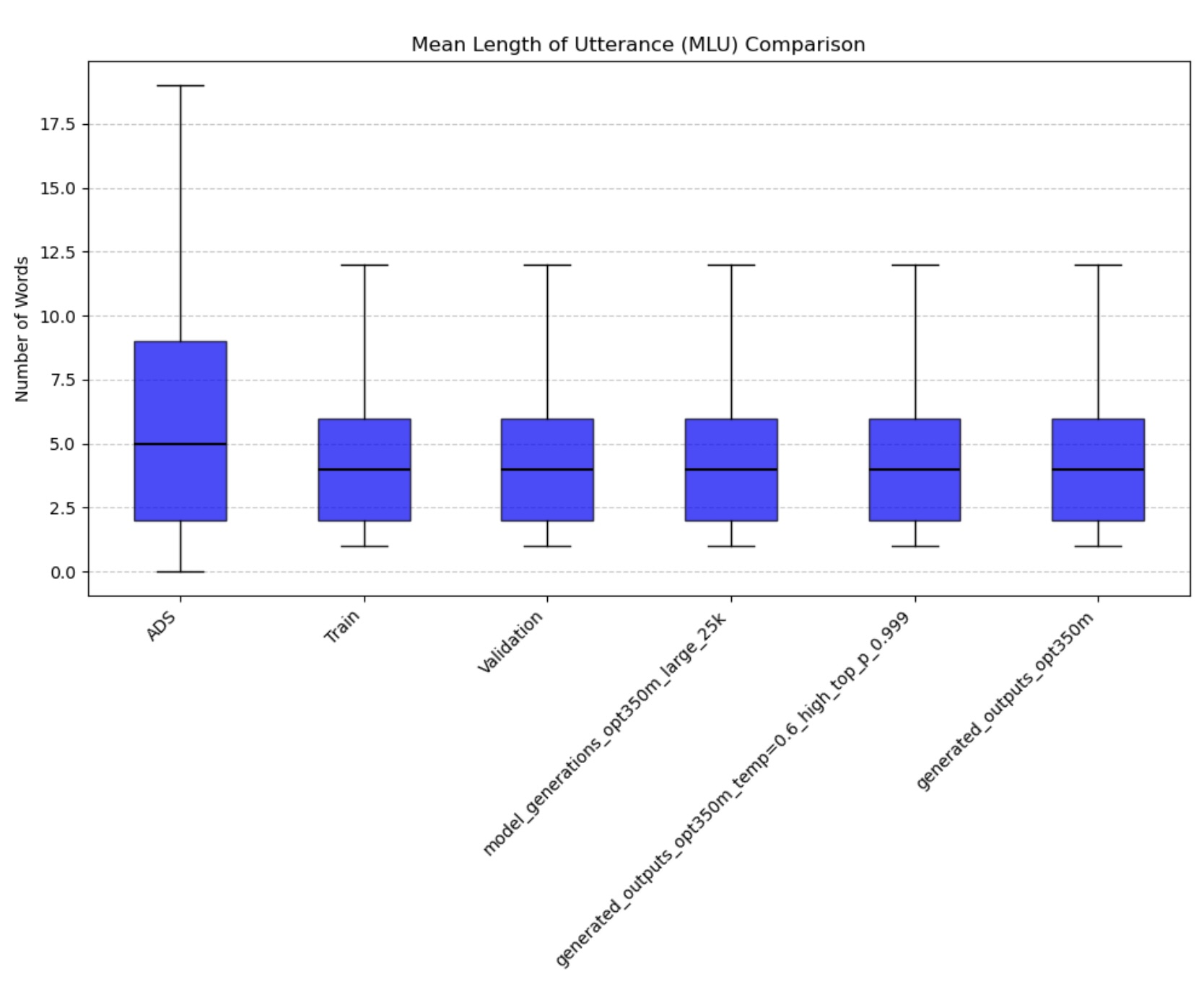
Figure 3: Mean Length of Utterance across all age groups
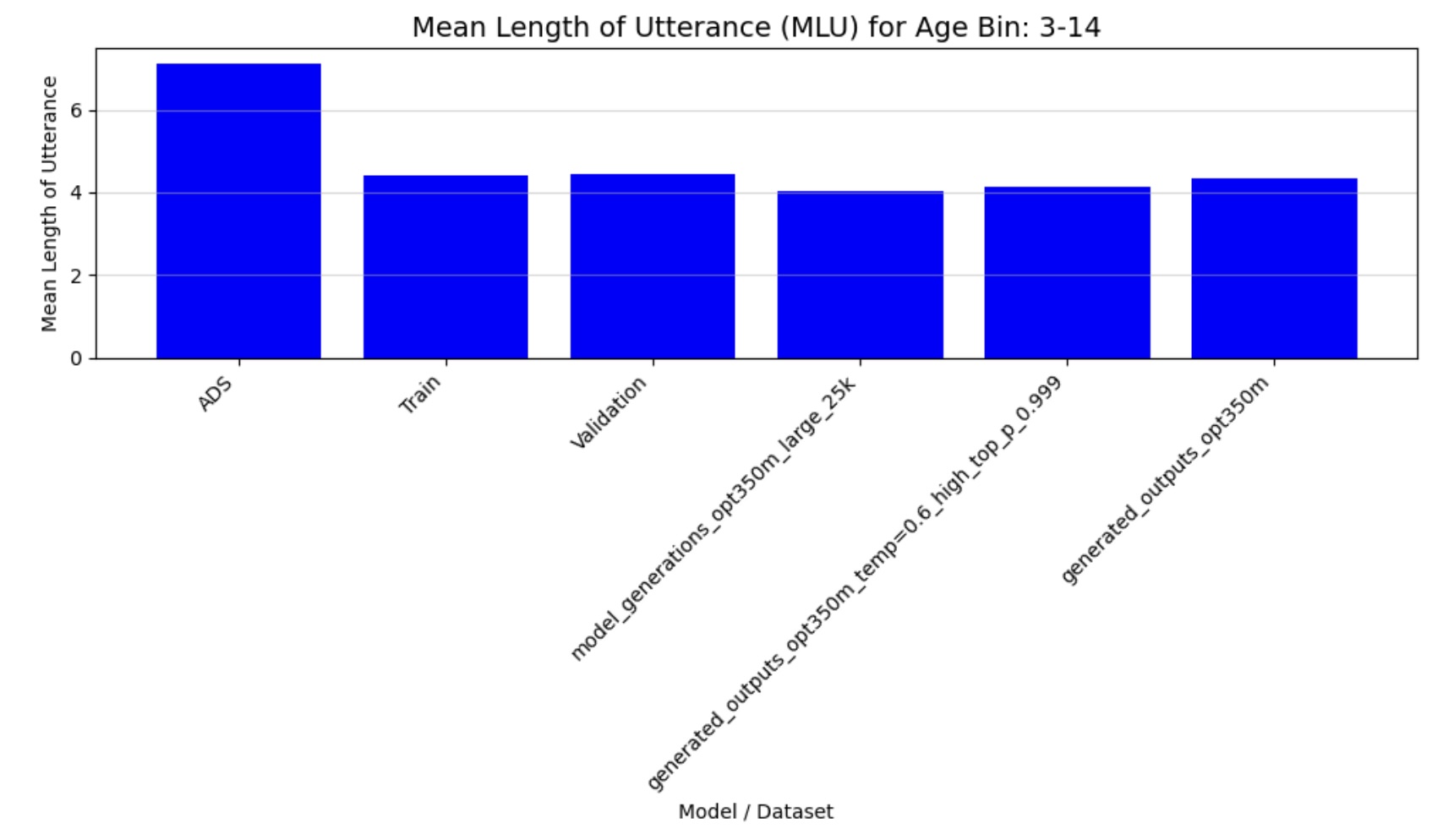
Figure 4a: Mean Length of Utterance (3-14 months)
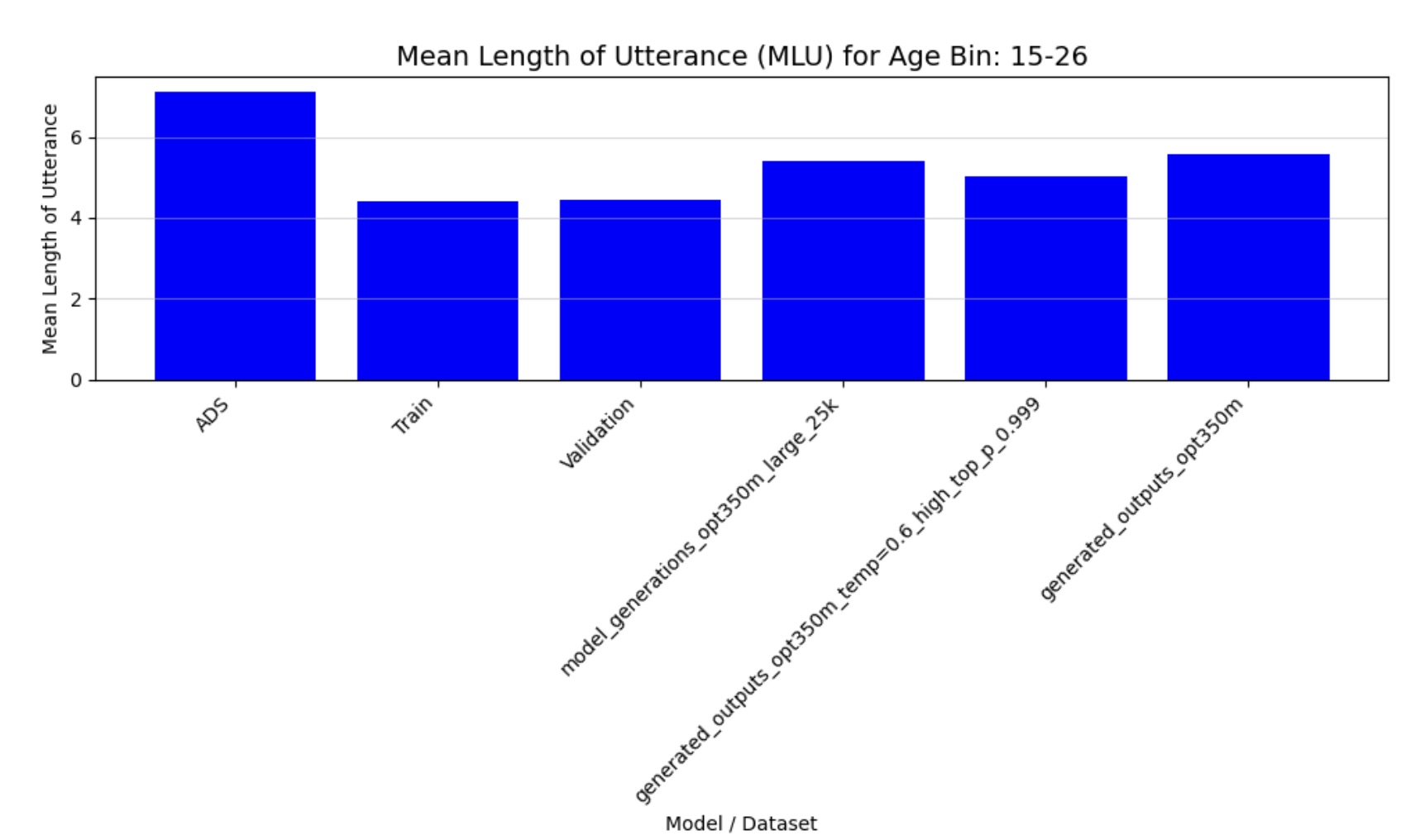
Figure 4b: Mean Length of Utterance (15-26 months)
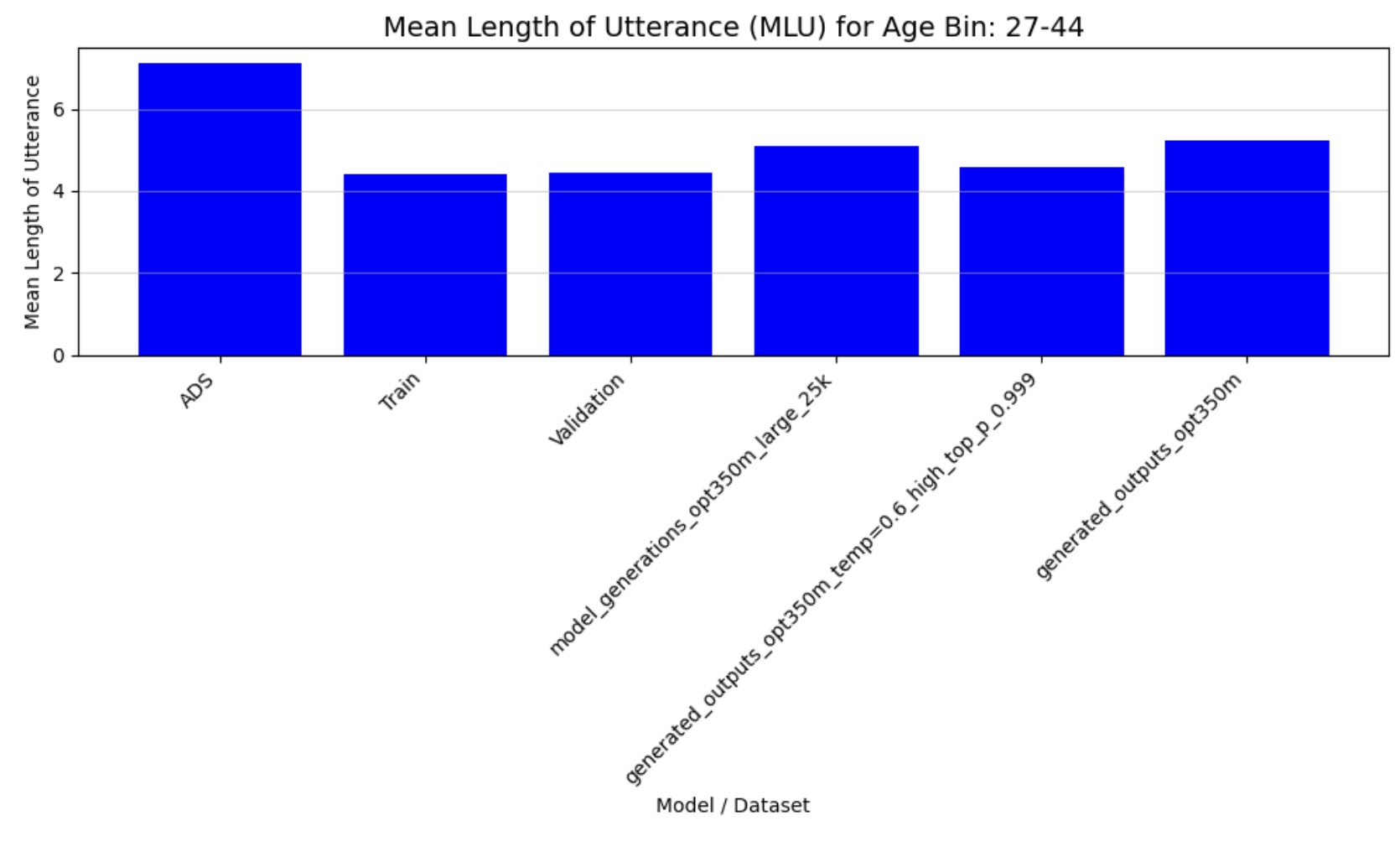
Figure 4c: Mean Length of Utterance (27-44 months)
- Word Frequency Distributions: Analyzes the statistical patterns of word usage to ensure realistic vocabulary patterns
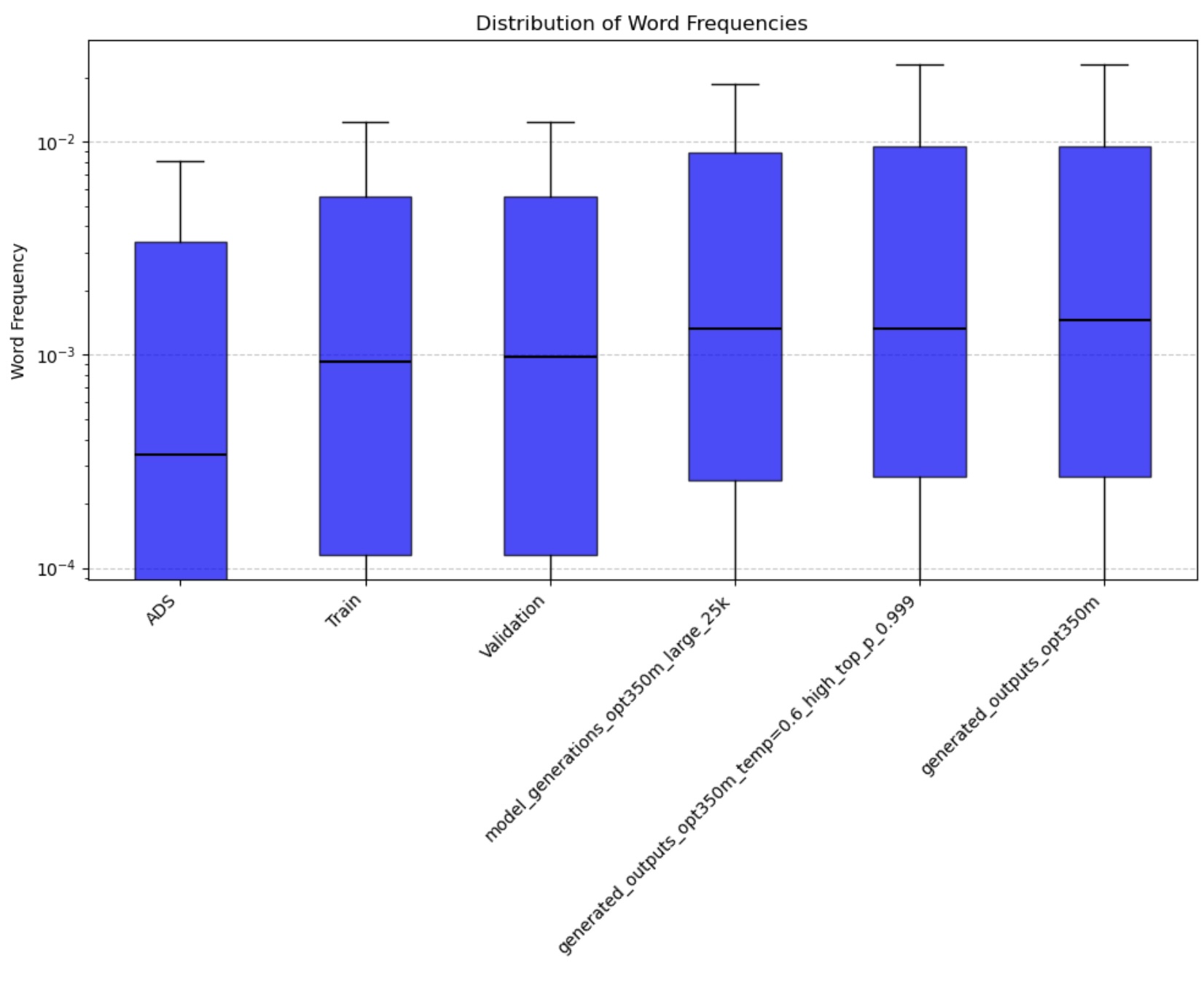
Figure 5: Word Frequency Distribution across all age groups
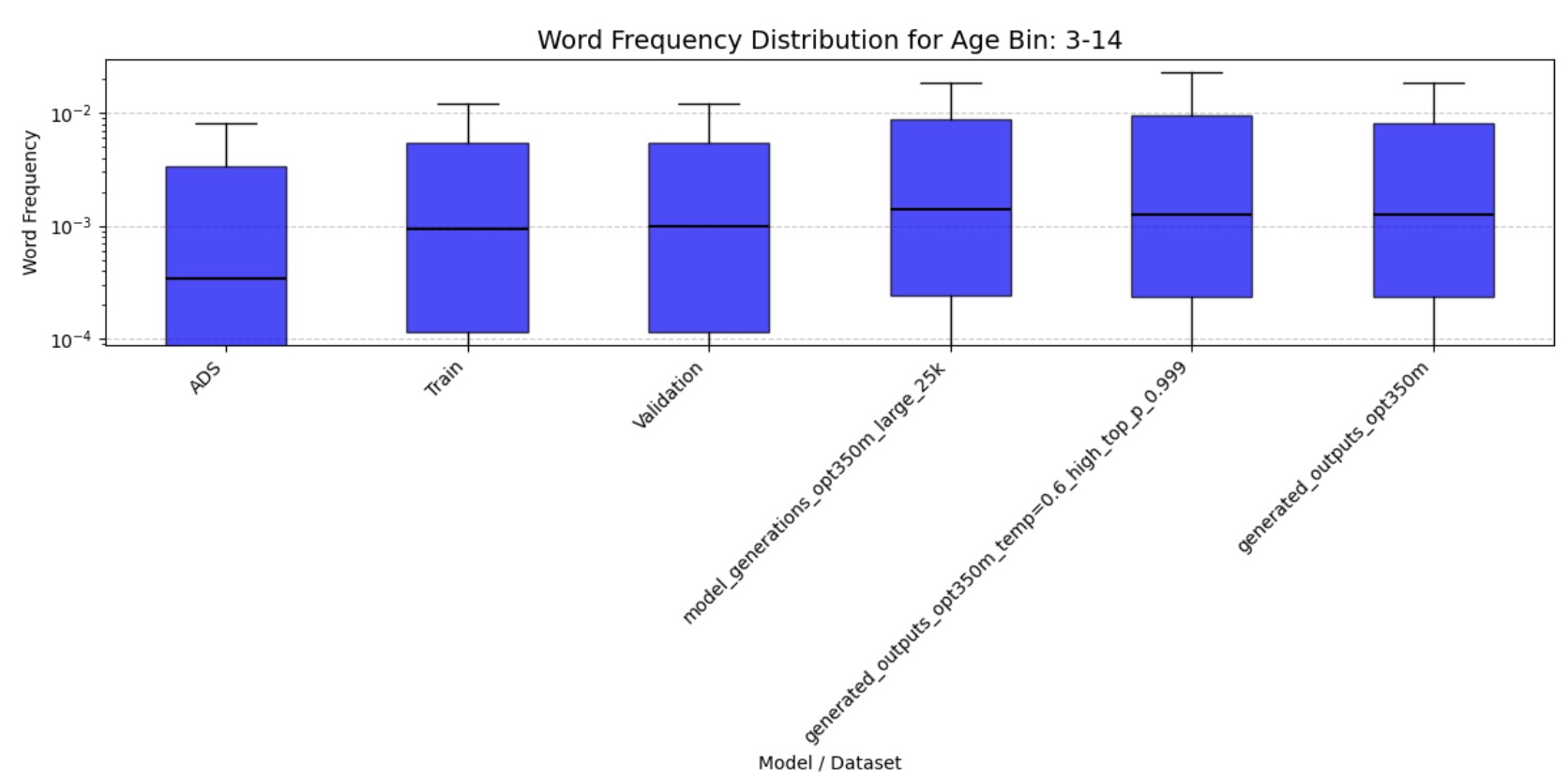
Figure 6a: Word Frequency Distribution (3-14 months)
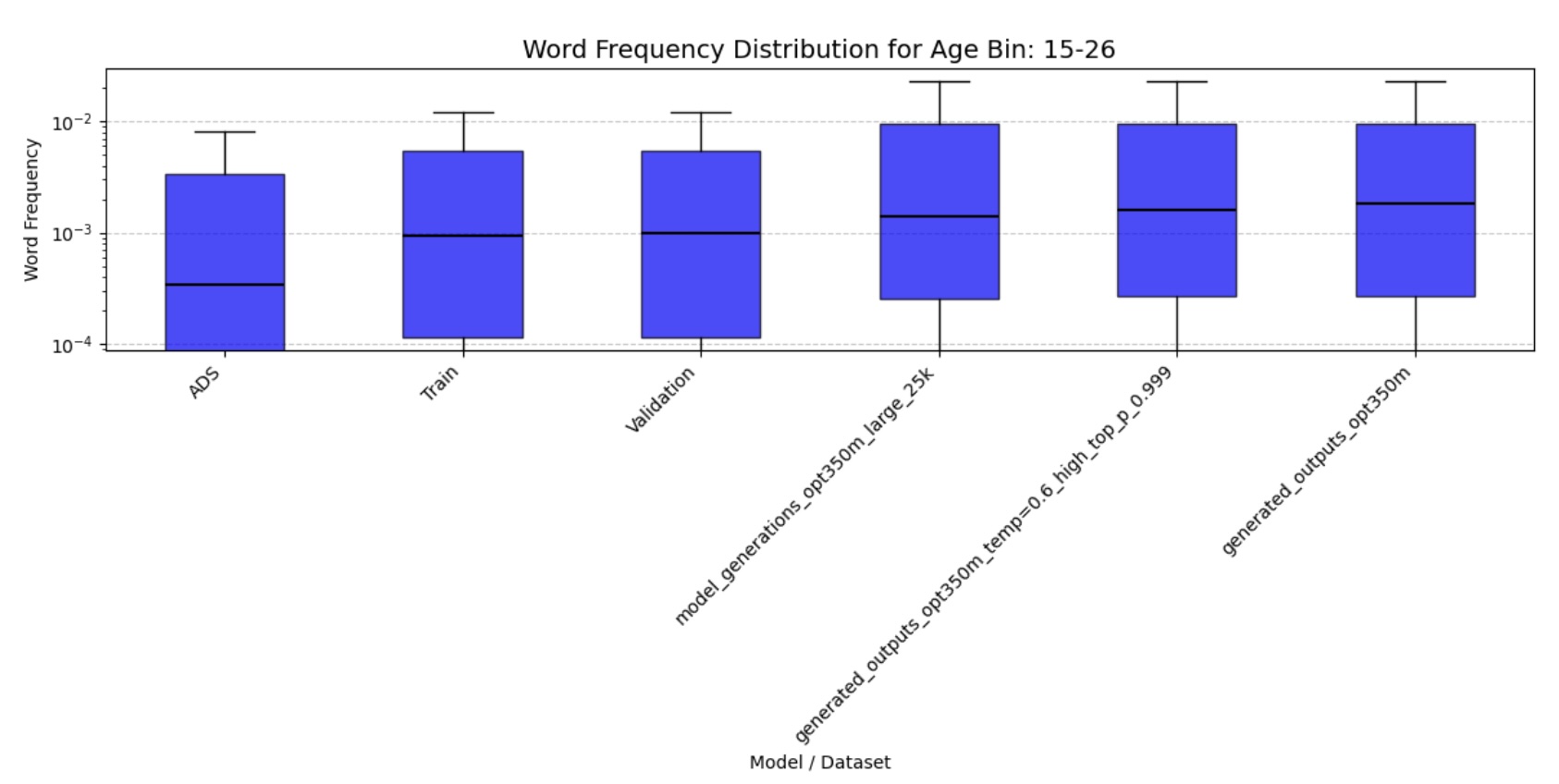
Figure 6b: Word Frequency Distribution (15-26 months)

Figure 6c: Word Frequency Distribution (27-44 months)
Conclusion
The quantitative analysis of our fine-tuned model’s output demonstrates strong alignment with real child-directed speech patterns. The moving average Type-Token Ratio (TTR), Mean Length of Utterance (MLU), and word frequency distributions of the generated speech closely match those observed in the CHILDES holdout set across all age groups (3-44 months). Importantly, these metrics differ significantly from adult-directed speech patterns, confirming that our model has successfully learned the distinctive characteristics of child-directed communication.
This empirical validation of our age-stratified fine-tuning methodology represents a significant advancement in creating developmentally appropriate artificial caregivers. The model’s ability to replicate the natural evolution of caregiver speech patterns across child development stages enables more precise experimental control in language acquisition research while maintaining ecological validity.
Future Work
The next phase of this research will focus on training the child-directed speech (CDS) model to generate the characteristic prosodic patterns of caregiver speech. We will fine-tune a speech synthesis model on carefully selected CDS audio samples from CHILDES, optimizing for features like exaggerated pitch contours, slower speaking rate, and clearer enunciation. The trained speech model will then be integrated with our fine-tuned LLM, creating an end-to-end system that can generate both age-appropriate text and speech that mimics natural caregiver communication patterns.
Stay tuned for upcoming posts detailing the speech model architecture, training methodology, and evaluation results. We will also share audio samples demonstrating the system’s ability to produce developmentally-tailored child-directed speech across different age ranges.
The complete implementation code and trained models will be made available upon publication of our research findings.